快速了解PyTorch
Most machine learning workflows involve:
- working with data
- creating models
- optimizing model parameters
- saving the trained models
We’ll use the FashionMNIST dataset to train a neural network that predicts if an input image belongs to one of the following classes: T-shirt/top, Trouser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, or Ankle boot.
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
## working with data
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
batch_size = 64
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
## creating models
# Get cpu or gpu device for training.
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using {device} device")
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
##optimizing model parameters
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")
##saving the trained models
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")
## loading and reuse the trained models
model = NeuralNetwork()
model.load_state_dict(torch.load("model.pth"))
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')
Pytorch API 介绍
Tensors are a specialized data structure that are very similar to arrays and matrices. In PyTorch, we use tensors to encode the inputs and outputs of a model, as well as the model’s parameters.
Tensors are similar to NumPy’s ndarrays, except that tensors can run on GPUs or other hardware accelerators. In fact, tensors and NumPy arrays can often share the same underlying memory, eliminating the need to copy data (see Bridge with NumPy). Tensors are also optimized for automatic differentiation (we’ll see more about that later in the Autograd section). If you’re familiar with ndarrays, you’ll be right at home with the Tensor API. If not, follow along!
1、Tensors 张量
2、Creation Ops 创建张量
3、Indexing, Slicing, Joining, Mutating Ops 张量变换
4、Generators 生成器
troch.Generators(), 用途??
5、Random sampling 随机抽样
6、Serialization 序列化(保存与加载)
7、Locally disabling gradient computation 局部禁用梯度计算
8、Math operations 数学运算
8.1 Pointwise Ops 元素运算
torch.mul(), 两个矩阵维数相同时,计算结果为对应元素相乘的结果,即点乘,否则按照矩阵的乘法规则计算,计算结果是矩阵
torch.dot(), 数量积,计算结果是标量
9、Reduction Ops 归纳操作
10、Comparison Ops 比较操作
11、Spectral Ops
12、Other Operations 其他操作
1、Containers 容器
1.1 Module
所有神经网络模块的基础类,常用的一些属性:modules(), parameters(), named_modules(), named_parameters()
1.2 Sequential
神经网络模块序列,
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Using Sequential with OrderedDict. This is functionally the
# same as the above code
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
2、Convolution Layers 卷积层
2.1 Conv1d
In the simplest case, the output value of the layer with input size $(N, C_{in}, L_{in})$ and output $(N,C_{out},L_{out})$ can be precisely described as:
\(out(N_i,C_{outj})=bias(C_{outj})+\sum_{k=0}^{C_{in}-1}weight(C_{outj,k})\star input(N_i,k)\)
where $\star$ is the valid cross-correlation operator, N is a batch size, C denotes a number of channels, L is a length of signal sequence.
\(L_{out}=\left\lfloor\frac{L_{in}+2 \times padding-dilation \times (kernel\_size-1)-1}{stride}+1 \right\rfloor\)
*括号表示向下取整
2.2 Conv2d
In the simplest case, the output value of the layer with input size $(N, C_{in}, H_{in}, W_{in})$ and output $(N,C_{out},H_{out}, W_{out})$ can be precisely described as:
\(out(N_i,C_{outj})=bias(C_{outj})+\sum_{k=0}^{C_{in}-1}weight(C_{outj,k})\star input(N_i,k)\)
where $\star$ is the valid 2D cross-correlation operator, N is a batch size, C denotes a number of channels, H is a height of input planes in pixels, and W is width in pixels.
\(H_{out}=\left\lfloor\frac{H_{in}+2 \times padding[0]-dilation[0] \times (kernel\_size[0]-1)-1}{stride[0]}+1 \right\rfloor\)
\(W_{out}=\left\lfloor\frac{W_{in}+2 \times padding[0]-dilation[0] \times (kernel\_size[0]-1)-1}{stride[0]}+1 \right\rfloor\)
2.2 Conv3d
In the simplest case, the output value of the layer with input size $(N, C_{in}, D_{in},H_{in}, W_{in})$ and output $(N,C_{out},D_{out},H_{out}, W_{out})$ can be precisely described as:
\(out(N_i,C_{outj})=bias(C_{outj})+\sum_{k=0}^{C_{in}-1}weight(C_{outj,k})\star input(N_i,k)\)
卷积过程 如下图:
1) 二维卷积,如下图是一个卷积核(kernel)为3×3、步长(stride)为1、填充(padding)为0的卷积:

更多类型可参考博文通过可视化直观了解卷积
3、Pooling layers 池化层
3.1 Max pooling
3.2 Average pooling
3.3 power-Average pooling
\(f(X)=\sqrt[p]{\sum_{x\in X}x^p}\)
3.4 Adaptive max pooling
3.5 Adaptive average pooling
4、Padding Layers 填充层
4.1 Reflection padding
使用输入张量的边际作为填充元素(边际镜像)
4.2 Replication padding
使用输入张量的边际作为填充元素(边际重复)
4.3 Zeros padding
使用0作为填充元素
4.4 Constant padding
使用常数作为填充元素
5、Non-linear Activations 非线性激活函数
加快训练速度,
| 函数 | 公式 | 图像 |
|---|---|---|
| nn.ELU | $ELU(x)=\begin{cases}x,&if\ x \gt 0 \ \alpha * (\exp(x) - 1), &if\ x \leq 0 \end{cases}$ | 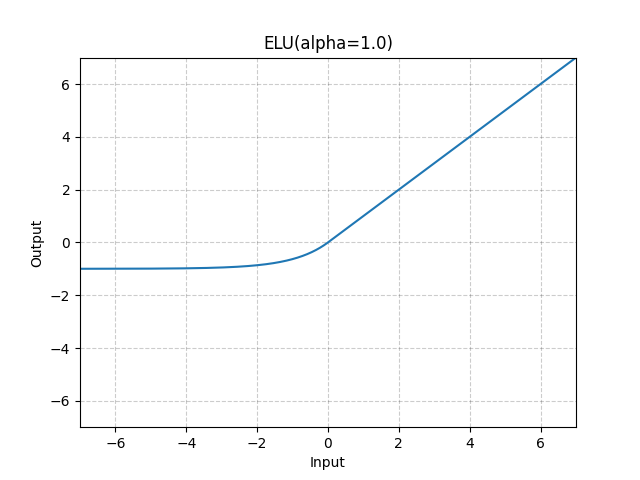 |
……
6、Normalization Layers 归一化层
6.1 Batch normalization
\(y=\frac{x-E[x]}{\sqrt{Var[x]+\epsilon}}*\gamma+\beta\)
6.2 Group normalization
6.3 Instance normaliztion
6.4 Layer normaliztion
6.5 local respose normalization
7、Recurrent Layers 循环层
7.1 RNN multi-layer Elman RNN, \(h_t=tanh(x_tW_{ih}^T+b_{ih}+h_{t-1}W_{hh}^T+b_{hh})\) where $h_t$ is the hidden state at time t, $x_t$ is the input at time t, and $h_{(t-1)}$ is the hidden state of the previous layer at time t-1 or the initial hidden state at time 0. If nonlinearity is ‘relu’, then $\text{ReLU}$ is used instead of $\tanh$.
7.2 LSTM
multi-layer long short-term memory (LSTM) RNN,
7.3 GRU
multi-layer gated recurrent unit (GRU) RNN
8、Transformer Layers
A transformer model. The architecture is based on the paper “Attention Is All You Need”. Ashish Vaswani.
9、Linear Layers 线性层/连接层
9.1 Linear
Applies a linear transformation to the incoming data:
\(y=xA^T+b\)
10、Dropout Layers
10.1 Dropout
During training, randomly zeroes some of the elements of the input tensor with probability p using samples from a Bernoulli distribution.
10.2 AlphaDropout
Alpha Dropout is a type of Dropout that maintains the self-normalizing property. For an input with zero mean and unit standard deviation, the output of Alpha Dropout maintains the original mean and standard deviation of the input. Alpha Dropout goes hand-in-hand with SELU activation function, which ensures that the outputs have zero mean and unit standard deviation.
11、Sparse Layers
11.1 Embedding
12、Distance Function
13、Loss Functions
如何选取损失函数:
到底该如何选择损失函数?
How to Choose Loss Functions When Training Deep Learning Neural Networks
13.1 Regression Loss Functions:
- Mean Squared Error Loss (MSE)
- Mean Squared Logarithmic Error Loss (MSLE)
- Mean Absolute Error Loss (MAE)
13.2 Binary Classification Loss Functions:
- Binary Cross-Entropy
- Hinge Loss
- Squared Hinge Loss
13.3 Multi-Class Classification Loss Functions:
- Multi-Class Cross-Entropy Loss
- Sparse Multiclass Cross-Entropy Loss
- Kullback Leibler Divergence Loss
14、Others 其他
torch.nn.functional与torch.nn的区别
| torch.nn.X | torch.nn.functional.X |
|---|---|
| 是类 | 是函数 |
| 结构中包含所需要初始化的参数 | 需要在函数外定义并初始化相应参数,并作为参数传入 |
| 一般情况下放在__init__中实例化,并在forward中完成操作 | 一般在__init__中初始化相应参数,在forward中传入 |
import torch
from torch import nn
import torch.nn.functional as F
inputs = torch.randn(20, 16, 50, 100)
# torch.nn.Conv2d
m = nn.Conv2d(in_channels=16, out_channels=33, kernel_size=3, stride=1, padding=0, bias=True)
output = m(inputs)
# torch.nn.functional.conv2d
filters = torch.randn(33, 16, 3, 3)
output2 = F.conv2d(input=inputs, weight=filters, bias=None, stride=1, padding=0)
torch.autograd provides classes and functions implementing automatic differentiation of arbitrary scalar valued functions. It requires minimal changes to the existing code - you only need to declare Tensor s for which gradients should be computed with the requires_grad=True keyword.
torch.optim is a package implementing various optimization algorithms. Most commonly used methods are already supported, and the interface is general enough, so that more sophisticated ones can be also easily integrated in the future.
模型优化算法。
梯度下降可沉甸,随机降低方差难。
引入动量别弯慢,Adagrad梯方贪。
Adadelta学率换,RMSProp梯方权。
Adam动量RMS伴,优化还需己调参。注释:
梯方:梯度按元素平方
贪:因贪婪故而不断累加
学率:学习率
数据处理和加载模块。
模型优化过程、结果展示。
Tensor类的方法和属性集
常见的线性代数运算。
Discrete Fourier transforms and related functions. 离散傅里叶变换。
未来版本接口。
TorchScript is a way to create serializable and optimizable models from PyTorch code. Any TorchScript program can be saved from a Python process and loaded in a process where there is no Python dependency.
We provide tools to incrementally transition a model from a pure Python program to a TorchScript program that can be run independently from Python, such as in a standalone C++ program. This makes it possible to train models in PyTorch using familiar tools in Python and then export the model via TorchScript to a production environment where Python programs may be disadvantageous for performance and multi-threading reasons.
模型部署。
torch.package adds support for creating hermetic packages containing arbitrary PyTorch code. These packages can be saved, shared, used to load and execute models at a later date or on a different machine, and can even be deployed to production using torch::deploy.
模型部署。
Subpackages
Transforming and augmenting images.
Models and pre-trained weights.
Biult-in datasets.
Three party libraries
- TorchMetrics,模型评估标准
经典的神经网络
可参考深度学习框架和代码收录网站 PapersWithCode
1、图像 1.1 图片分类:





1.2 目标检测:



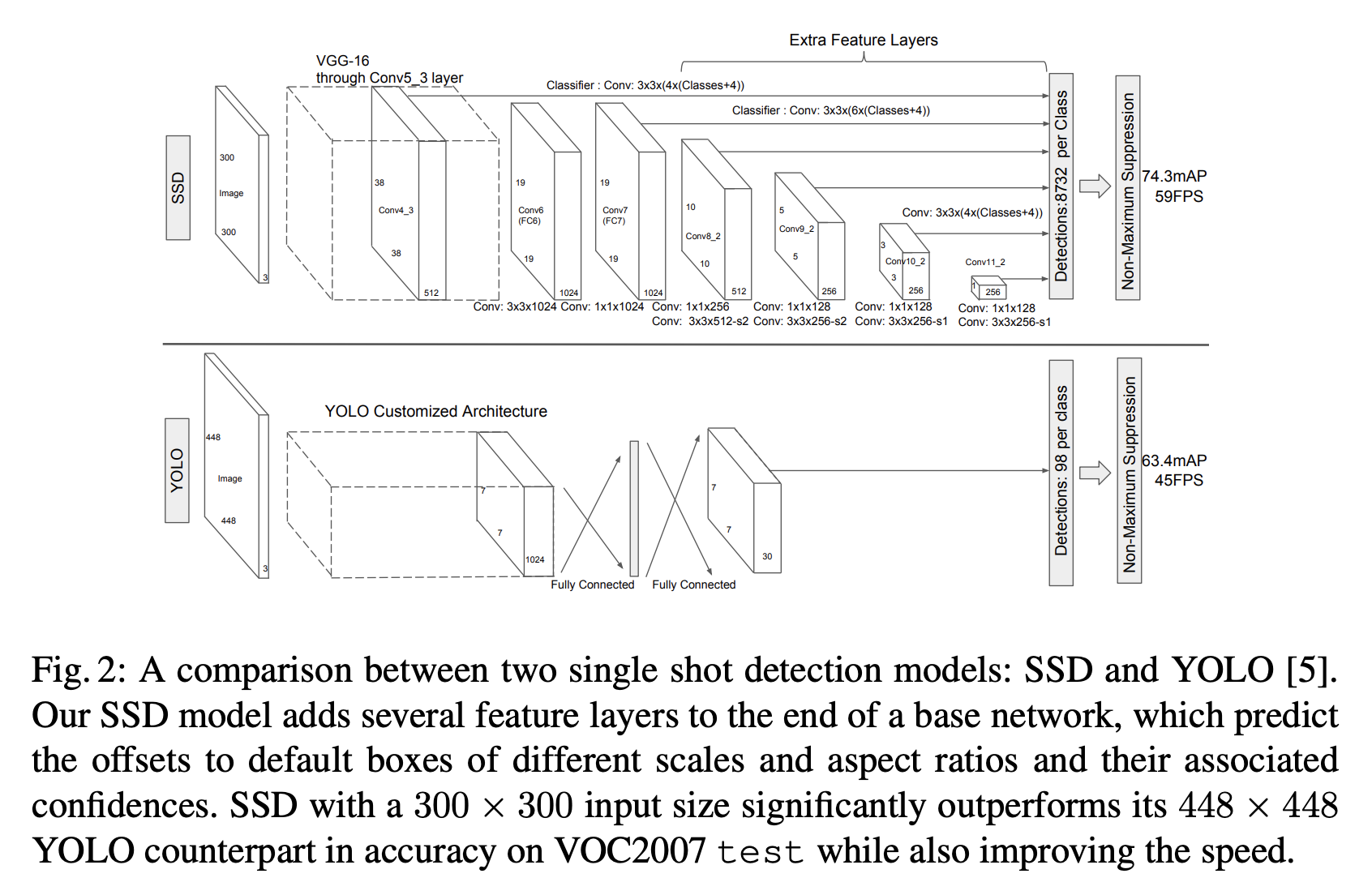
1.3 语义分割:

1.4 样式迁移:
1.5 图片生成:
- GAN, 对抗神经网络

2、序列 2.1 文本分类:


2.2 机器翻译:


2.3 NLP:


